



1 日志压缩逻辑存在严重问题
设备运行期间会产生大量日志,直接存储很容易遇到磁盘空间不足的风险,因此需要对日志文件进行压缩。
原有的压缩逻辑中,直接将整个日志文件一次性加载到内存,瞬时几百MB的内存消耗,对内存造成极大的压力,存在诸多风险:
内存压力过大时,操作系统可能会触发OOM(Out of Memory)机制,直接杀死占用内存过多的进程;
影响其它服务正常运行,可能导致其它服务不可用;
内存占用过高会导致系统频繁进行垃圾回收,增加CPU的负载,影响整体性能;
更大的日志文件,意味着更高的风险,风险不可控;
因此需要优化日志压缩算法。除了内存风险之外,同时考虑不同压缩率、不同压缩算法和算法压缩速率,优化日志压缩算法。
2 压缩逻辑优化
压缩方式根据其工作方式可以分为三种类型:
流式压缩:预先不可知文件大小,边读边压缩,低内存
块式压缩:预先分块处理,可并行
文件压缩:整体压缩,高压缩率
原先的逻辑是这里的“文件压缩”,由于日志文件并不像网络视频或音频这种流式的数据,所以更适合“块式压缩”。
对比原先的整体的“文件压缩”,“块式压缩”可以预先对文件进行分块,块大小固定(比如1MB),每次加载一块数据到内存中,避免了内存出现瞬时峰值。由于分块的大小会影响压缩速度和压缩率,还需要进一步对不同分块(如128KB、256KB...1MB、2MB...)做对比试验。
3 压缩算法对比
6种压缩算法:zstd、pzstd、brotli、lz4、gzip、pigz。
最终对100个文件近100G数据进行测试,测试指标有CPU占用、内存占用、总压缩时间、平均压缩时间、平均压缩速度,压缩速度方差、平均压缩率、压缩率方差。综合各种因素,最终选取zstd算法,绑定某个CPU核,进行生产环境中的压缩任务。
绑核指令:
taskset -c <核心编号> <COMMAND> # 核心编号可以指定多个,用逗号分隔4 哈夫曼编码(Huffman Coding)
详细信息参考我的另一篇博客:哈夫曼编码。
哈夫曼编码(Huffman Coding)是一种无损熵编码技术,其核心思想是:出现频率越高的符号用越短的码字,频率越低的符号用越长的码字,从而在整体上使平均码长逼近信源熵的理论下限。
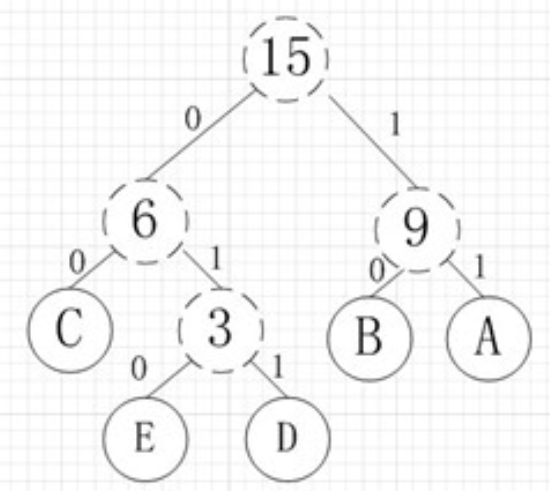
哈夫曼编码的核心时构建一棵哈夫曼树,具体步骤:
统计每个符号的出现频率;
将所有符号作为叶子节点,根据频率升序排列;
每次取出频率最低的两个节点,合并为一个新节点,其频率为两者之和;
将新节点差回队列,继续合并直到只剩下一个根节点;
从根节点到叶子节点,左分支记为0,右分支记为1,得到每个副奥的比特编码。
有A,B,C,D,E五个字符,出现的频率(即权值)分别为5,4,3,2,1:
评论区