



1 Framework of ML
1.1 Training Data
1.2 Training
1.2.1 Step 1: function with unknown
\boldsymbol \thetais unkonwn parameters, and \boldsymbol xis feature.
1.2.2 Step 2: define loss from training data
1.2.3 Step 3: optimization
1.3 Testing Data
Usey = f_{\boldsymbol \theta^*}(\boldsymbol x)to label the testing data, and we can get the result:
2 General Guilde
Judging the problem of the current model based on loss:
2.1 Model Bias
If the model loss is large on training data, it may be due to Model Bias.
The current model is not flexible enough and cannot fit the training data well.
Solution: redesign your model to make it more flexible, such as more features, neurons, layers.
2.2 Optimization Issue
If the model loss is large on training data, it may be due to Optimization Issue.
The current model optimization method has limitations, such as the local minima of the Gradient Descent.
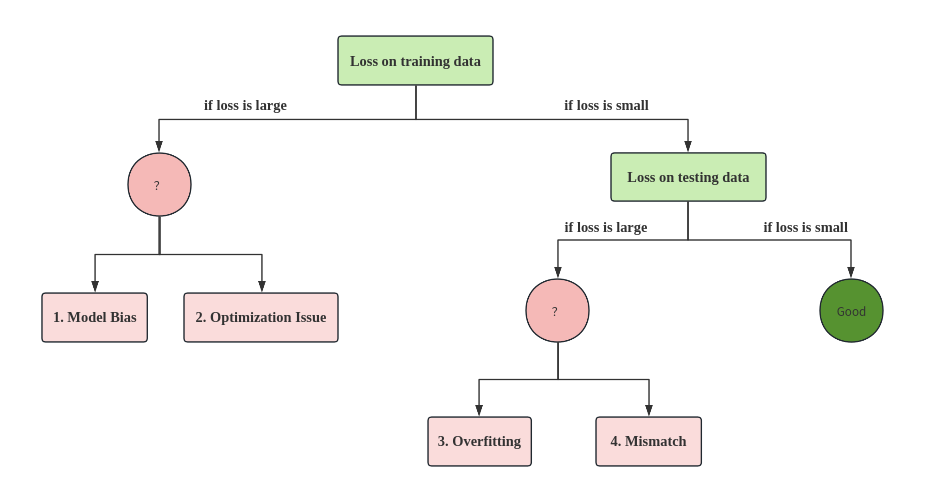
How to identify whether it is Model Bias or Optimization Issue?
Gaining the insights from comparison
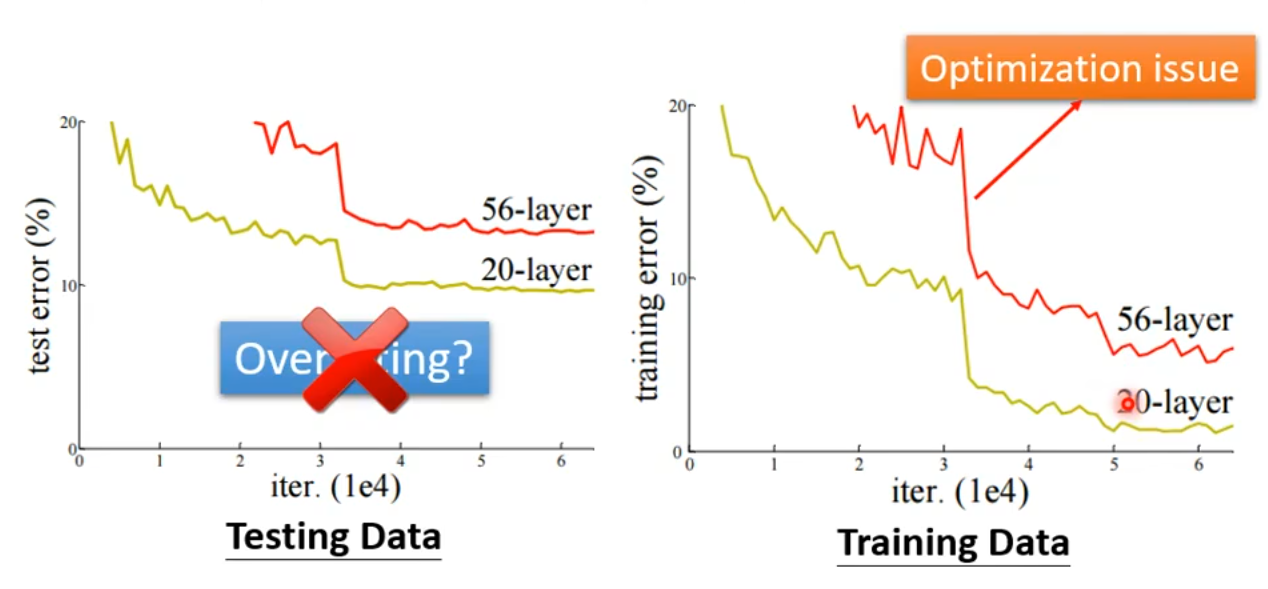
When we find that 56-layer model is worse than 26-layer model on testing data, what can we say? Overfitting?
NO! Only when the deeper model is worse on testing data but better on training data, we consider Overfitting. When the deeper model is worse on testing data and training data simultaneously, it's obviously NOT Overfitting, and it's NOT Model Bias, but why?
If Model Bias, it should be that the deeper model is better on testing data and training data simultaneously, and loss is still large even it is deeper. Remember? Model Bias means the model has limitation itself.
Actually, it's Optimization issue. Generally, the deeper model is more likely to have better result, because the deeper model is more flexible, and it should be >= the shallower model. But if the optimization method has limitation itself or other problems, it may be worse in deeper.
In real training tasks, we should observe results on Training Data first. Start from shallower model (or other simple models), which are easier to optimize, if deeper models obtain smaller loss on Training Data, then there is Optimization Issue.
Let's look at an example (different layer model's results on training data):

On training data, 1-layer model, 2-layer model, ..., deeper and better. But 5-layer model is worse than 4-layer model, we can conclude: it's Optimization Issue.
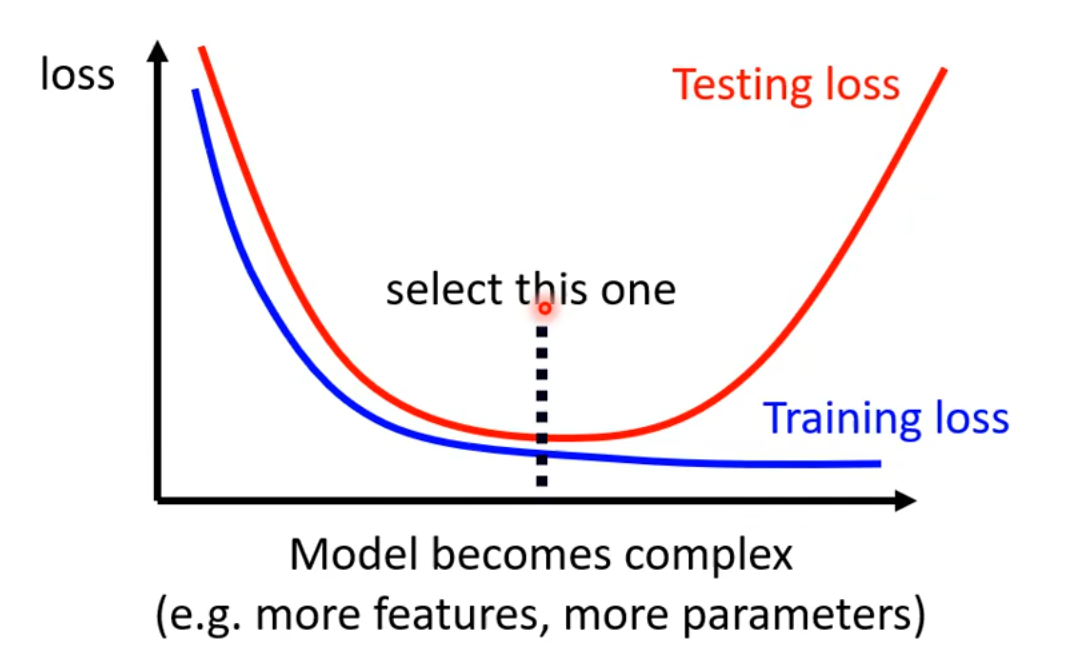
2.3 Overfitting
If the model loss is samll on training data, but large on testing data, it may be due to Overfitting.
The more flexible the model, the more likely it is to suffer from overfitting.
Solution:
1 More training data: collect more data.
2 Data augmentation: from existing data.
3 Constrained model:
Less parameters, shareing parameters, less features, early stopping, regularization, dropout.

2.4 Mismatch
If the model loss is samll on training data, but large on testing data, it may be due to Mismatch.
training data and testing data have different distribution:

3 Training Data
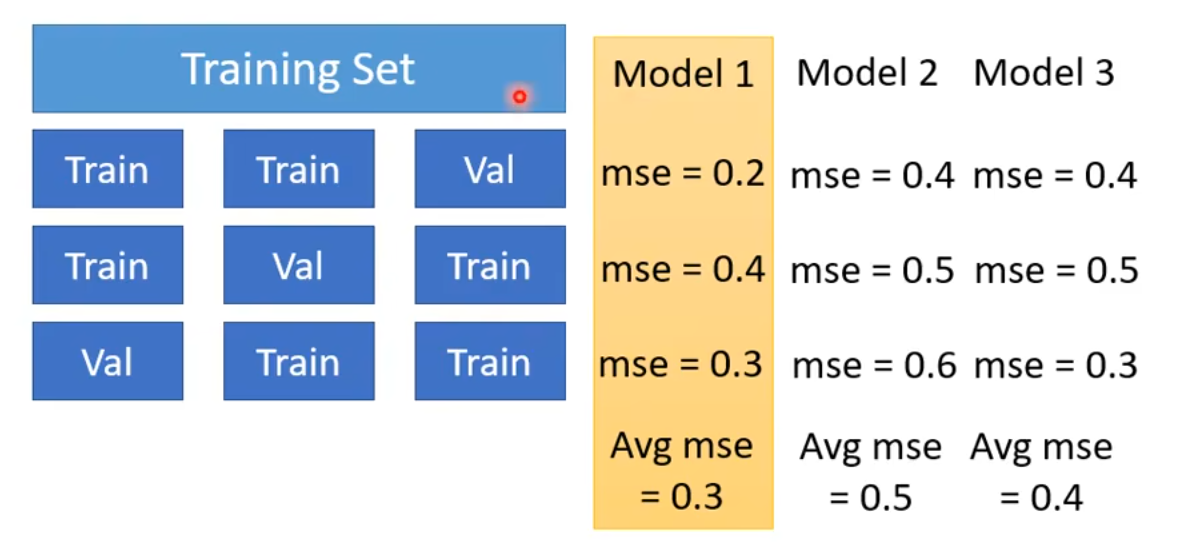
Generally, we should split training data into Training Set and Validation Set, and choose the best model on Validation Set to test on testing data.
How to split? N-fold Cross Validation:
评论区